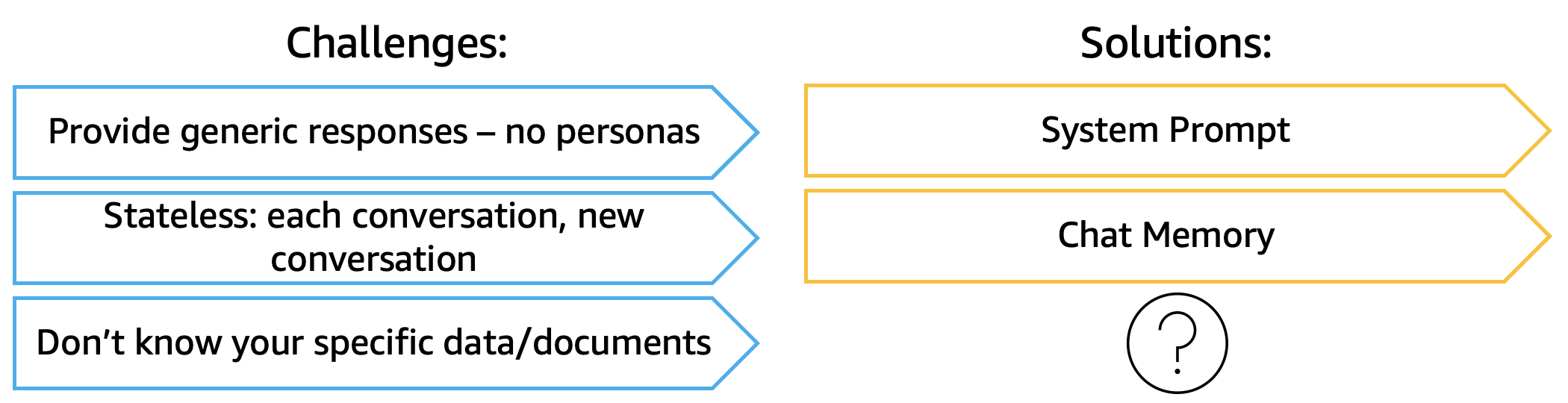
In Part 1 of this series, we built a functional AI agent using Java, Spring AI, and Amazon Bedrock. However, we discovered a critical limitation: the agent couldn’t remember previous conversations. When we asked “What is my name?” after introducing ourselves, the agent had no recollection of our earlier interaction.
This lack of memory creates a frustrating user experience and limits the agent’s usefulness for real-world applications. Imagine a customer service agent that forgets your issue every time you send a message, or a travel assistant that can’t recall your preferences from previous conversations.
In this post, we’ll enhance our AI agent with a three-tier memory architecture that provides both short-term conversation context and long-term user knowledge. We’ll implement this incrementally, starting with persistent session memory, then adding conversation summaries, and finally user preferences—all backed by PostgreSQL for production reliability.
Overview of the Solution
What is Spring AI Chat Memory?
Spring AI provides Chat Memory components that automatically manage conversation history:
Automatic Context Injection: Messages are automatically included in prompts to the AI model
The framework handles the complexity of managing conversation state, allowing you to focus on your application logic.
Choosing the Right Memory Store
Spring AI supports multiple memory storage backends:
Storage Type
Use Case
Pros
Cons
InMemory
Development, testing
Fast, simple setup
Lost on restart, not scalable
JDBC
Production apps with existing DB
Reliable, ACID compliant, familiar
Requires database
Redis
High-performance caching
Very fast, distributed
Additional infrastructure
Cassandra
Massive scale
Highly scalable
Complex setup
MongoDB
Document-oriented apps
Flexible schema
Additional infrastructure
Neo4j
Graph-based relationships
Rich relationship queries
Specialized use case
We chose JDBC (PostgreSQL) because:
✅ Most Spring Boot applications already use a relational database ✅ No additional infrastructure needed ✅ ACID compliance ensures data reliability ✅ Familiar SQL tooling for debugging and monitoring ✅ Easy migration to managed services like Amazon Aurora
Prerequisites
Before you start, ensure you have:
Completed Part 1 of this series with the working ai-agent application
Docker Desktop running (for Testcontainers to manage PostgreSQL)
AWS CLI configured with access to Amazon Bedrock
Navigate to your project directory from Part 1:
1
cd ai-agent
PostgreSQL with Testcontainers
We need a database for persistent memory storage. Manually installing and configuring PostgreSQL is tedious and error-prone. We want something that “just works” for development and easily transitions to production.
Why Testcontainers?
Testcontainers automatically manages Docker containers for your application. With container reuse enabled, the PostgreSQL container persists between application restarts—perfect for development!
Benefits:
✅ No manual PostgreSQL installation
✅ Automatic startup and configuration
✅ Data persists between app restarts (with reuse)
✅ Easy migration to production databases
When deploying to production, switch to Amazon Aurora PostgreSQL or any managed database by setting environment variables:
/** * Test application that starts with Testcontainers PostgreSQL. * Run with: ./mvnw spring-boot:test-run * * Container reuse enabled: same container persists between restarts. * To enable reuse: add "testcontainers.reuse.enable=true" to ~/.testcontainers.properties */ publicclassTestAiAgentApplication {
Creating container for image: pgvector/pgvector:pg16 Container pgvector/pgvector:pg16 is starting... Container pgvector/pgvector:pg16 started Started AiAgentApplication in X.XXX seconds
✅ Success! The PostgreSQL container is now running!
You can verify with:
1
docker ps | grep ai-agent-postgres
Stop the application (Ctrl+C) and next time when you start again — the same container is reused with data intact!
Commit Changes
1 2
git add . git commit -m "Add Testcontainers for PostgreSQL"
Three-Tier Memory Architecture
Real applications need multiple types of memory for different purposes. Users expect the agent to remember who they are (preferences), what they’ve discussed (context), and the current conversation flow (session).
Why Three Tiers?
Each tier serves a distinct purpose:
Tier
Storage
Purpose
Example
Session
20 messages
Current conversation flow
“What did we just talk about?”
Context
10 summaries
Historical discussions
“What topics have we covered?”
Preferences
1 profile
Static user information
“Who is this user?”
This separation allows efficient memory management—session handles immediate context, context tracks decisions over time, and preferences store unchanging user details (name, email, dietary restrictions). All three tiers use JDBC for persistence across restarts.
Architecture Overview
1 2 3 4 5 6 7 8 9 10 11
User Question ↓ [Session Memory] ← JDBC/PostgreSQL (20 recent messages) ↓ [Context Memory] ← JDBC/PostgreSQL (10 conversation summaries) ↓ [Preferences Memory] ← JDBC/PostgreSQL (1 user profile) ↓ AI Model (Amazon Bedrock) ↓ Response
Create ChatMemoryService
Create the service that manages all three memory tiers:
publicChatMemoryService(DataSource dataSource) { // Single JDBC repository shared by all three memory tiers varjdbcRepository= JdbcChatMemoryRepository.builder() .dataSource(dataSource) .dialect(newPostgresChatMemoryRepositoryDialect()) .build();
public Flux<String> callWithMemory(ChatClient chatClient, String prompt) { StringconversationId= getCurrentConversationId();
// 1. Auto-load previous context on first message if (sessionMemory.get(conversationId).isEmpty()) { loadPreviousContext(conversationId, chatClient); }
// 2. Add user message to session memory sessionMemory.add(conversationId, newUserMessage(prompt));
// 3. Stream AI response with full conversation history StringBuilderfullResponse=newStringBuilder(); return chatClient .prompt(newPrompt(sessionMemory.get(conversationId))) .stream() .content() .doOnNext(fullResponse::append) .doOnComplete(() -> { // 4. Save complete response to session memory StringresponseText= fullResponse.toString(); if (!responseText.isEmpty()) { sessionMemory.add(conversationId, newAssistantMessage(responseText)); logger.info("Saved response to memory: {} chars", responseText.length()); } }); }
// 2. Combine preferences and summaries StringBuildercontextBuilder=newStringBuilder(); if (!preferencesText.isEmpty()) { contextBuilder.append("User Preferences:\n").append(preferencesText).append("\n\n"); } if (!summaries.isEmpty()) { contextBuilder.append("Previous Conversations:\n"); summaries.forEach(msg -> contextBuilder.append(msg.getText()).append("\n\n")); }
// 3. Summarize combined context with AI varchatResponse= chatClient.prompt() .user("Summarize this user information concisely:\n\n" + contextBuilder) .call() .chatResponse();
if (contextSummary == null || contextSummary.isEmpty()) { logger.warn("Failed to generate context summary"); return; }
// 4. Add context as system message to session memory StringcontextMessage= String.format( "You are continuing a conversation with this user. Here is what you know:\n\n%s\n\n" + "Use this information to provide personalized responses.", contextSummary ); sessionMemory.add(conversationId, newSystemMessage(contextMessage)); logger.info("Loaded context summary"); }
// Getters and setters public MessageWindowChatMemory getSessionMemory() { return sessionMemory; }
public MessageWindowChatMemory getContextMemory() { return contextMemory; }
public MessageWindowChatMemory getPreferencesMemory() { return preferencesMemory; }
public Flux<String> processChat(String prompt) { logger.info("Processing chat: '{}'", prompt); try { return chatMemoryService.callWithMemory(chatClient, prompt); } catch (Exception e) { logger.error("Error processing chat", e); return Flux.just("I don't know - there was an error processing your request."); } } ...
Conversation Summary
Session memory holds 20 recent messages, but long conversations exceed this limit. We need to summarize conversations and extract two types of information:
Context: What was discussed, decisions made, topics covered
Preferences: Who the user is, their preferences, static information
Why Separate Context and Preferences?
Context changes: Each conversation adds new topics and decisions
Preferences persist: User’s name, email, dietary restrictions don’t change that often
Efficient updates: Only update what changed, preserve what didn’t
Create ConversationSummaryService
Create a service that extracts both context and preferences:
public String summarizeAndSave(String conversationId) { logger.info("Summarizing conversation: {}", conversationId);
// 1. Get session messages and existing preferences List<Message> messages = chatMemoryService.getSessionMemory().get(conversationId); if (messages.isEmpty()) { return"No conversation to summarize"; }
// 3. Generate AI summary (preferences + context) StringpreferencesPrompt= existingPrefsText.isEmpty() ? "Extract static user information (name, email, preferences). If none, return empty." : "Merge preferences. Keep existing:\n" + existingPrefsText + "\nAdd new from conversation. Update only if explicitly changed. Keep existing if unchanged.";
varchatResponse= chatClient.prompt() .user("Analyze this conversation and provide TWO separate summaries:\n\n" + "PREFERENCES:\n" + preferencesPrompt + "\n\n" + "CONTEXT:\n" + "Summarize: topics discussed, questions asked, decisions made, pending items.\n" + "DO NOT include: prices, dates, flight numbers, hotel names, policies.\n\n" + "Output format:\n===PREFERENCES===\n[preferences]\n===CONTEXT===\n[context]\n\n" + "Conversation:\n" + messagesText) .call() .chatResponse();
private String getUserId(String requestUserId, Principal principal) { // Production: use authenticated user from Spring Security if (principal != null) { return principal.getName().toLowerCase(); } // Development: use provided userId or default return requestUserId != null ? requestUserId.toLowerCase() : "user1"; }
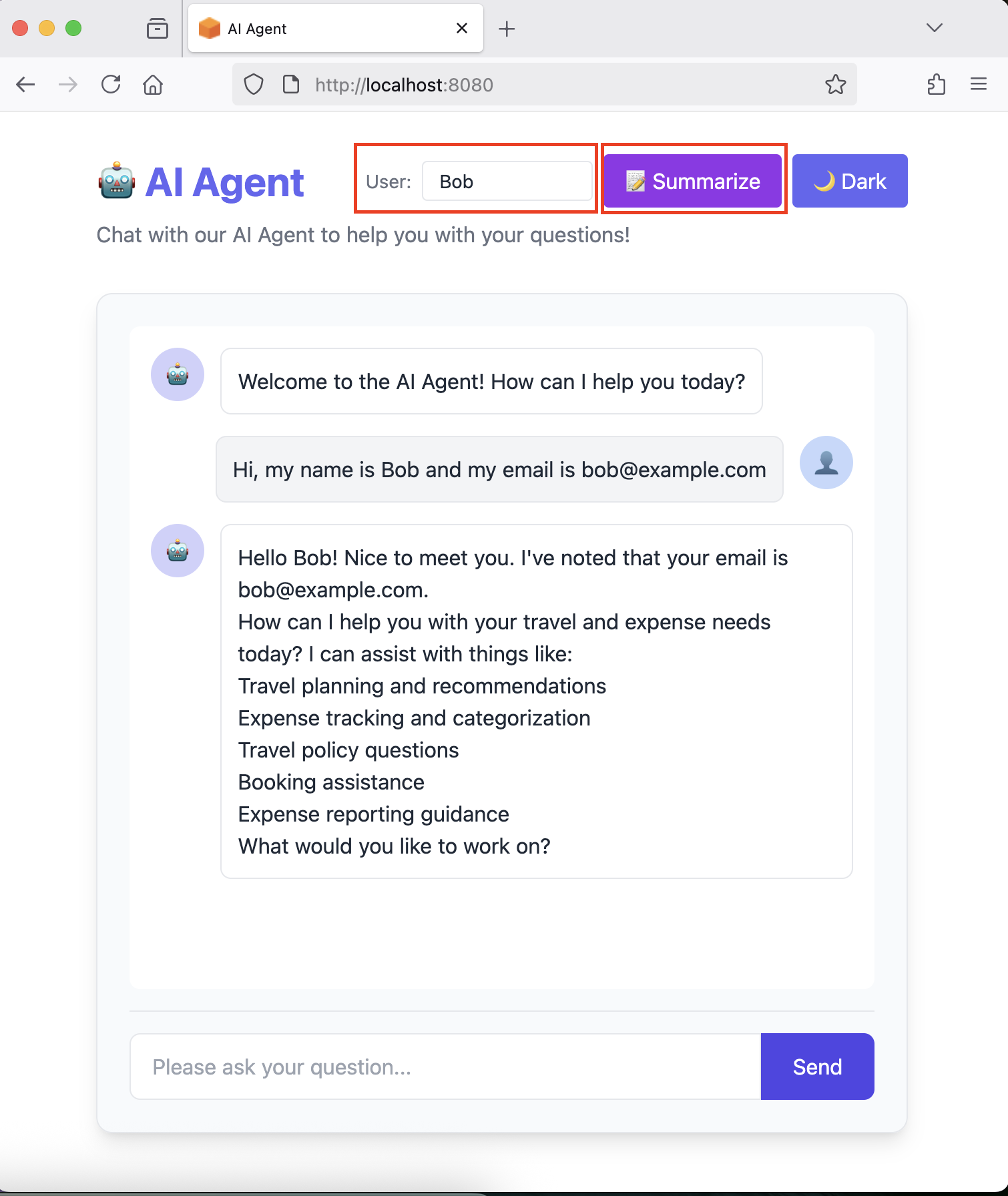
# Alice introduces herself curl -X POST http://localhost:8080/api/chat/message \ -H "Content-Type: application/json" \ -d '{"prompt": "Hi, my name is Alice and my email is [email protected]", "userId": "alice"}' \ --no-buffer
# Alice shares travel plans curl -X POST http://localhost:8080/api/chat/message \ -H "Content-Type: application/json" \ -d '{"prompt": "I am planning a trip to Paris next week for a conference", "userId": "alice"}' \ --no-buffer
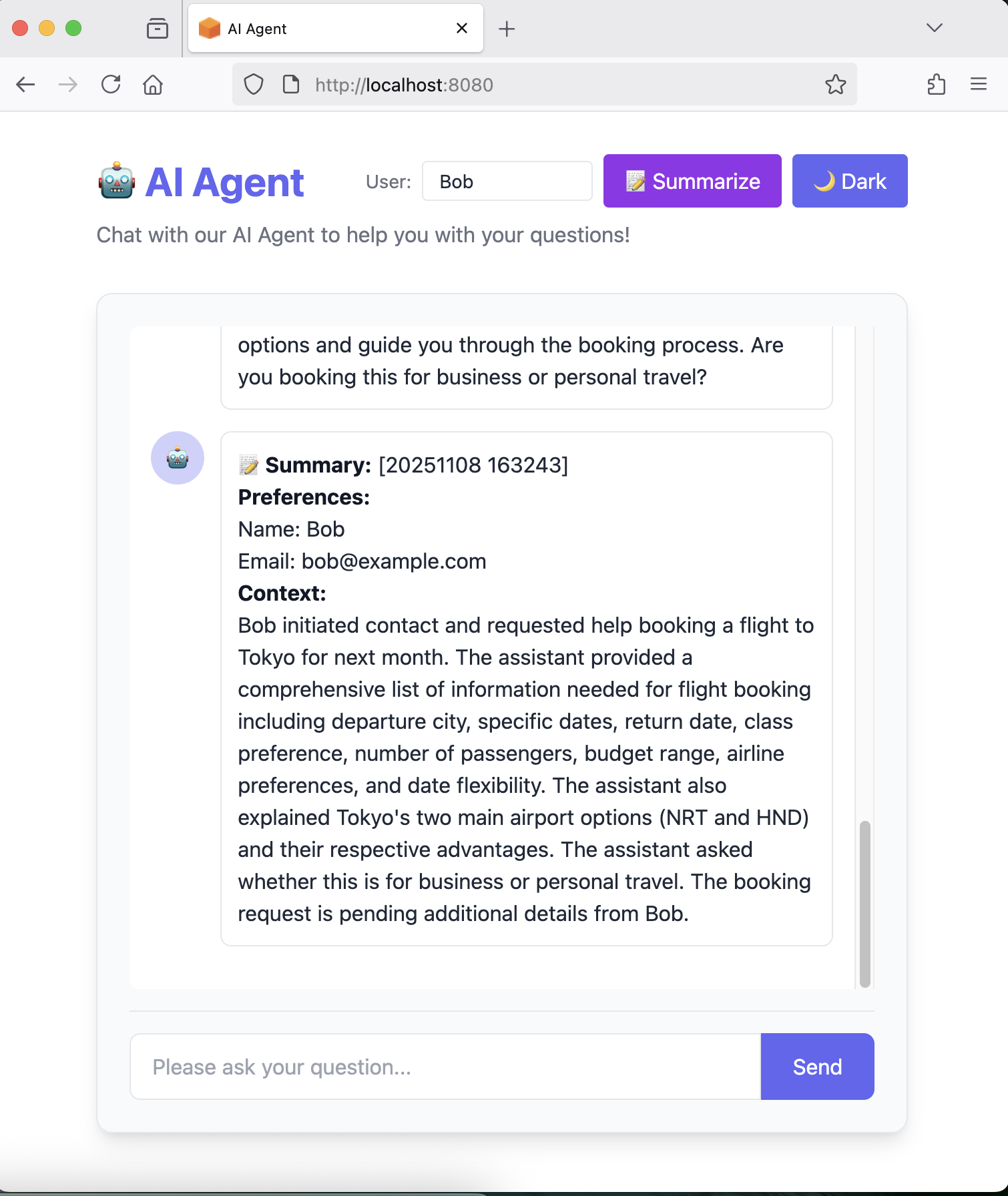
**Context:** Alice is planning a business conference trip to Paris next week. The assistant offered comprehensive travel assistance and asked for additional details including travel dates, conference venue location, accommodation status, departure city, expense reimbursement information, budget planning needs, travel preferences, and whether she needs recommendations or policy guidance. Alice has not yet provided responses to these questions, leaving multiple planning aspects pending.%
You can also test in the UI at http://localhost:8080 - use the “📝 Summarize” button and switch between users with the User ID field.
Test with Bob to verify multi-user isolation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# Bob introduces himself curl -X POST http://localhost:8080/api/chat/message \ -H "Content-Type: application/json" \ -d '{"prompt": "Hi, my name is Bob and my email is [email protected]", "userId": "bob"}' \ --no-buffer
# Bob shares different travel plans curl -X POST http://localhost:8080/api/chat/message \ -H "Content-Type: application/json" \ -d '{"prompt": "I need to book a flight to Tokyo for next month", "userId": "bob"}' \ --no-buffer
Now test if Alice’s agent remembers her information (not Bob’s):
1 2 3 4 5 6 7 8 9 10 11 12 13
# Ask about Alice's email curl -X POST http://localhost:8080/api/chat/message \ -H "Content-Type: application/json" \ -d '{"prompt": "What is my email address?", "userId": "alice"}' \ --no-buffer # Response: "Your email address is [email protected]"
# Ask about Alice's travel plans curl -X POST http://localhost:8080/api/chat/message \ -H "Content-Type: application/json" \ -d '{"prompt": "What are my recent travel plans?", "userId": "alice"}' \ --no-buffer # Response includes: Paris, conference, next week (NOT Tokyo)
✅ Success! All three memory tiers work together with proper user isolation!
Let’s continue the chat:
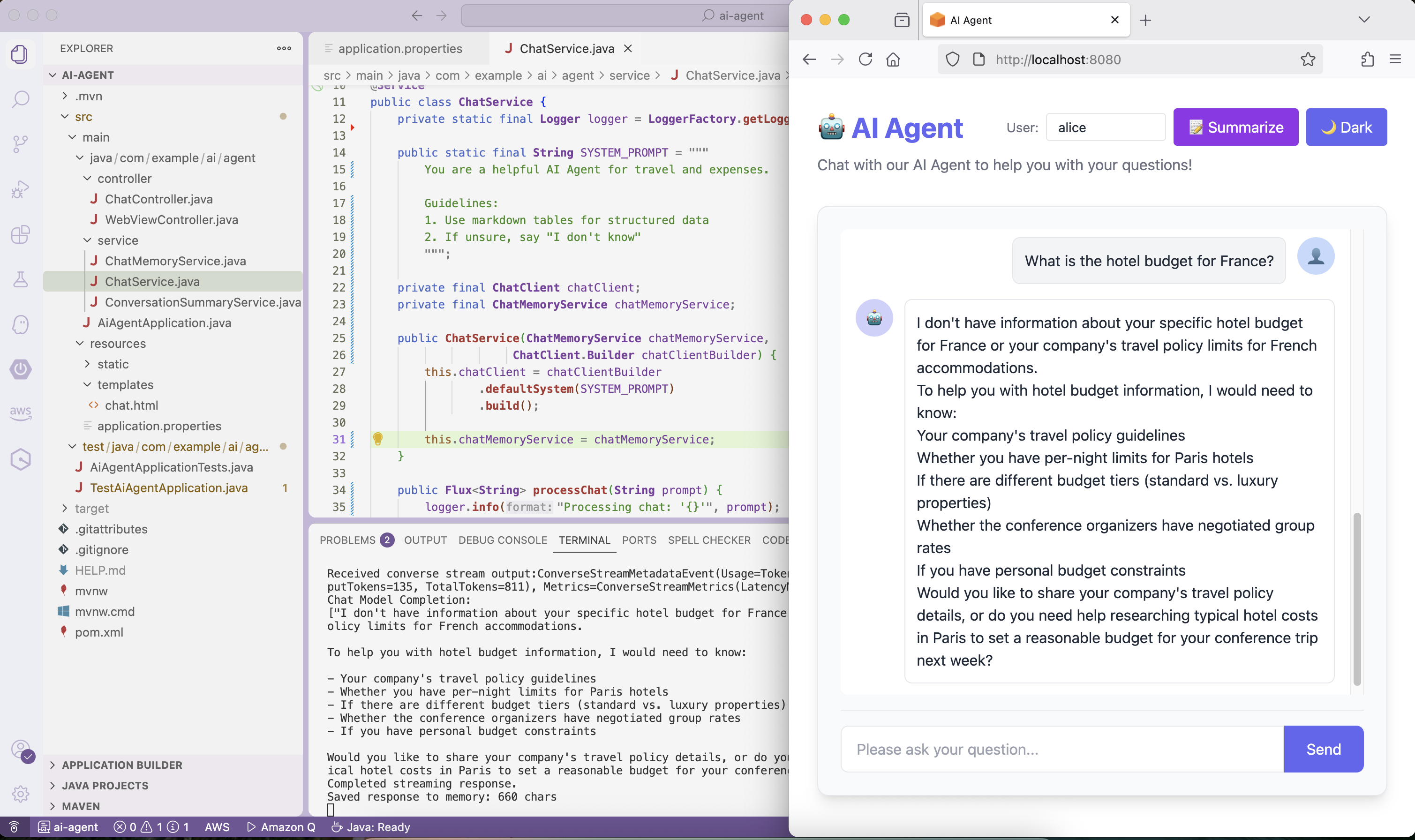
1 2 3 4 5
curl -X POST http://localhost:8080/api/chat/message \ -H "Content-Type: application/json" \ -d '{"prompt": "What is the hotel budget for France?", "userId": "alice"}' \ --no-buffer # Response: "I don't have information about your specific hotel budget for France or your company's travel policy limits for French accommodations."
❌ Problem: The agent doesn’t have access to company-specific knowledge like travel policies.
We’ll address this in the next part of the series! Stay tuned!
Cleanup
To stop the application, press Ctrl+C in the terminal where it’s running.
The PostgreSQL container will continue running (due to withReuse(true)). If necessary, stop and remove it:
git add . git commit -m "Add conversation summarization with context and preferences"
Conclusion
In this post, we’ve enhanced our AI agent with a production-ready three-tier memory system:
Session Memory: 20 recent messages persisted in PostgreSQL
Context Memory: 10 conversation summaries with timestamps
Preferences Memory: Long-term user profile information
Auto-load: Previous context loaded automatically on first message
Multi-user support: Isolated conversations per user
AI-powered summarization: Extracts both context and preferences
Testcontainers: Zero-configuration PostgreSQL for development
The three-tier memory architecture provides the foundation for personalized, context-aware AI agents that remember both who users are and what they’ve discussed.
What’s Next
Add knowledge to our AI agent. The agent will finally be able to answer questions like “What is the hotel budget for France?” by searching through travel and expense policies.