
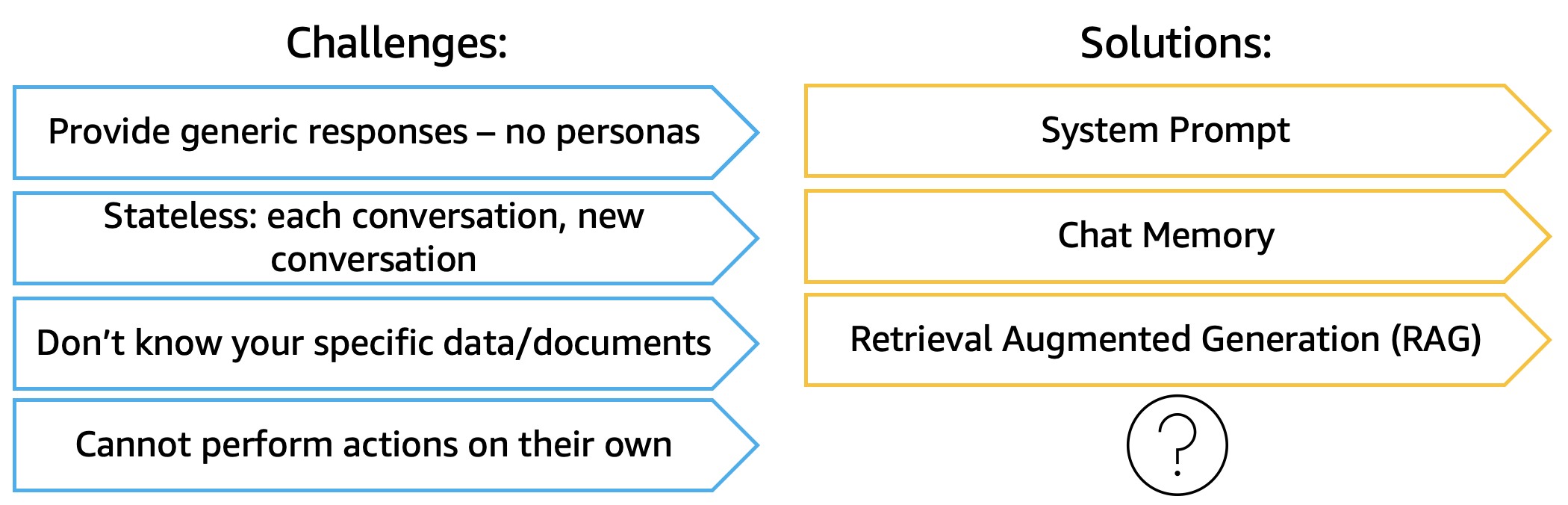
In Part 2 of this series, we enhanced our AI agent with conversation memory, allowing it to remember previous interactions and maintain context across sessions. However, we discovered another critical limitation: when asked about company-specific information like travel policies, the agent couldn’t provide accurate answers.
Generic AI models are trained on broad internet data but don’t know your company’s specific policies, procedures, or domain knowledge. They might provide plausible-sounding but incorrect answers (hallucinations), which is unacceptable for business applications.
In this post, we’ll add domain-specific knowledge to our AI agent through RAG (Retrieval-Augmented Generation), allowing it to answer questions based on company documents with accuracy and confidence.
Overview of the Solution
We’ll solve the knowledge problem with RAG (Retrieval-Augmented Generation):
- Convert company documents (travel policy) into vector embeddings
- Store embeddings in a vector database (PGVector)
- Automatically retrieve relevant sections when users ask questions
- Ground AI responses in actual company documents
What are vector embeddings?
Vector embeddings are numerical representations of words, sentences, or other data types in a continuous vector space, where similar meanings are located close together. For example, the vectors for “Paris” and “France” will be close to each other—just as “Tokyo” and “Japan” are—because the model learns their relationship through context. This concept allows computers to understand semantic similarity and is widely used in search engines, recommendation systems, and chatbots.
Architecture Overview
1 | User Question |
Key Spring AI Components
- QuestionAnswerAdvisor: Automatically retrieves relevant documents for RAG
- PGVector: PostgreSQL extension for vector similarity search
- Titan Embeddings: Amazon Bedrock’s embedding model
Prerequisites
Before you start, ensure you have:
- Completed Part 2 of this series with the working
ai-agentapplication - Java 21 JDK installed (Amazon Corretto 21)
- Maven 3.6+ installed
- Docker Desktop running (for Testcontainers with PostgreSQL/PGVector)
- AWS CLI configured with access to Amazon Bedrock
- Access to Amazon Bedrock models (specifically Titan Embeddings) in your AWS account
Navigate to your project directory from Part 2:
1 | cd ai-agent |
Travel Policy and RAG
Why RAG?
RAG (Retrieval-Augmented Generation) grounds AI responses in actual documents, eliminating hallucinations and ensuring accuracy.
Why PGVector?
Spring AI supports multiple vector databases:
- PGVector (PostgreSQL extension - what we’ll use)
- OpenSearch
- Pinecone
- Weaviate
- Milvus
- Chroma
- Redis
We chose PGVector because:
- ✅ Reuses existing PostgreSQL database (from Part 2)
- ✅ Single database for both memory and knowledge
- ✅ No additional infrastructure needed
- ✅ OpenSearch and other specialized vector databases are excellent for large-scale production, but add complexity
- ✅ PGVector is sufficient for most applications
For large-scale production with millions of documents, consider dedicated vector databases like OpenSearch or Pinecone.
Add RAG Dependencies
Open pom.xml and add these dependencies to the <dependencies> section:
1 | <!-- RAG Dependencies --> |
Configure Titan Embeddings and PGVector:
1 | cat >> src/main/resources/application.properties << 'EOF' |
Create Travel Policy
Create the company travel and expense policy document:
1 | mkdir -p samples |
Create VectorStoreService and Controller
Create a service to load documents into the vector store:
1 | cat <<'EOF' > src/main/java/com/example/ai/agent/service/VectorStoreService.java |
Create a controller to expose the load endpoint:
1 | cat <<'EOF' > src/main/java/com/example/ai/agent/controller/VectorStoreController.java |
Why separate controller? The
/api/admin/rag-loadendpoint is for administrative purposes (loading company documents) and will require different security permissions (ROLE_ADMIN) than user-facing chat endpoints (ROLE_USER).
Update ChatService with RAG
Add QuestionAnswerAdvisor to ChatService:
src/main/java/com/example/ai/agent/service/ChatService.java
1 | ... |
Testing Knowledge
Let’s test the RAG system with policy questions:
1 | ./mvnw spring-boot:test-run |
In another terminal, load the policy document:
1 | curl -X POST http://localhost:8080/api/admin/rag-load \ |
Test with REST API:
1 | # Test hotel budget question |
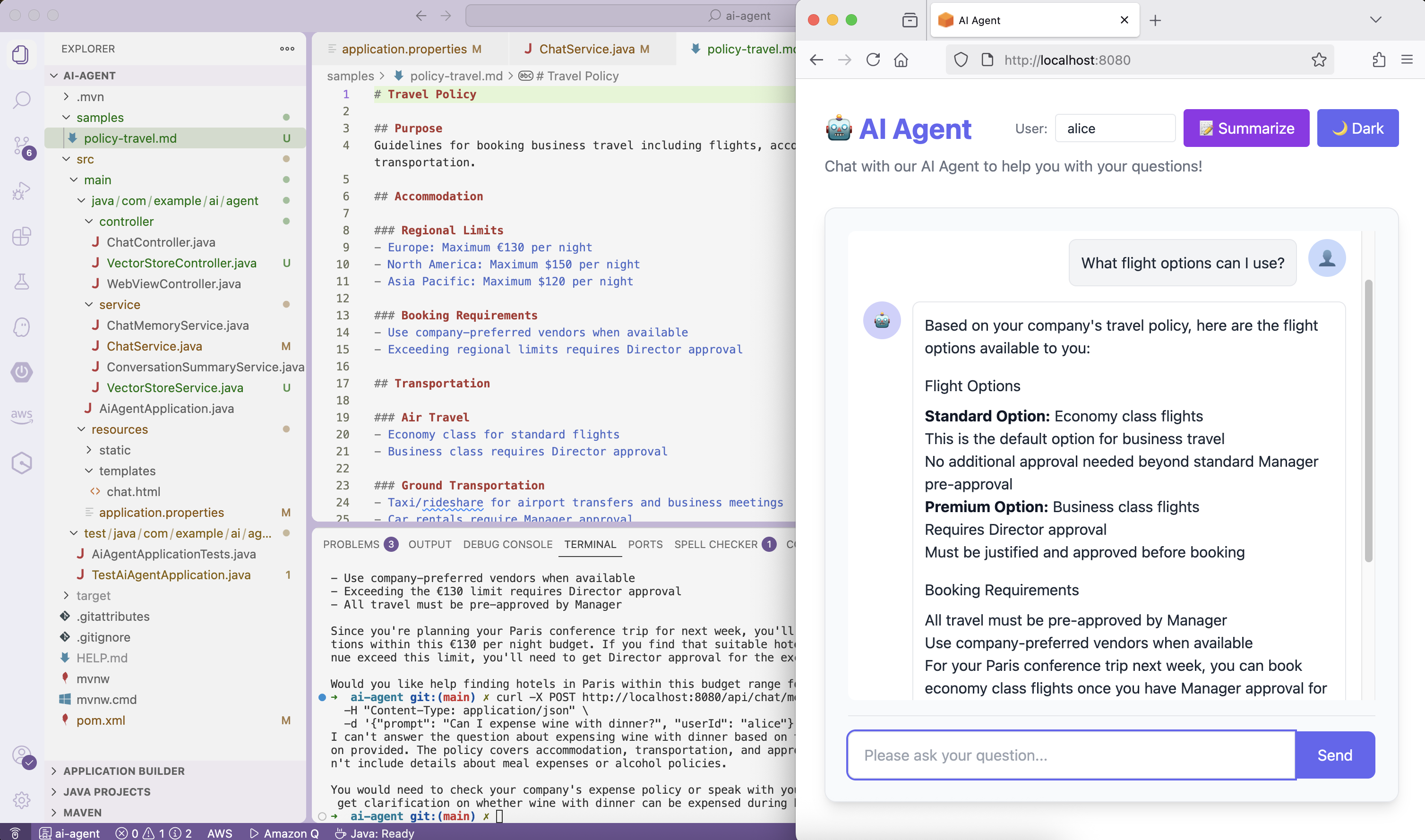
✅ Success! The agent provides accurate policy information grounded in company documents.
You can also test in the UI at http://localhost:8080 - ask policy questions and see grounded responses.
Let’s continue the chat:
1 | curl -X POST http://localhost:8080/api/chat/message \ |
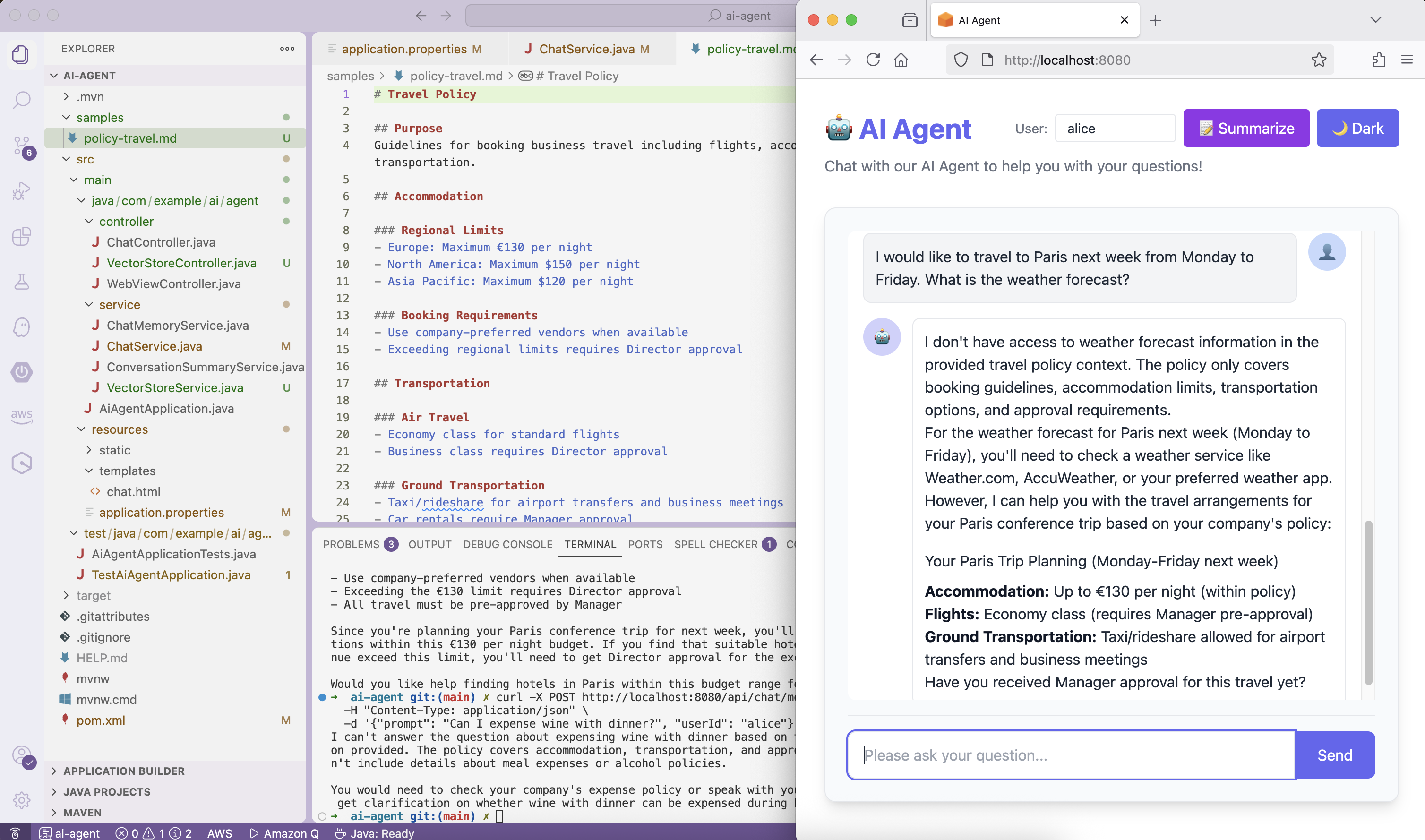
❌ Problem discovered: The agent can’t perform actions and access real-time information like the current date and the weather forecast.
We’ll address this limitation in the next part of the series! Stay tuned!
Cleanup
To stop the application, press Ctrl+C in the terminal where it’s running.
The PostgreSQL container will continue running (due to withReuse(true)). If necessary, stop and remove it:
1 | docker stop ai-agent-postgres |
(Optional) To remove all data and start fresh:
1 | docker volume prune |
Commit Changes
1 | git add . |
Conclusion
In this post, we’ve added domain-specific knowledge to our AI agent through RAG:
- PGVector for vector similarity search
- Titan Embeddings for semantic understanding
- QuestionAnswerAdvisor for automatic context retrieval
- Grounded responses in company documents
The foundation we’ve built—memory and knowledge—is essential for any production AI agent. You now have the tools to create intelligent assistants that remember conversations and provide accurate, domain-specific information.
What’s Next
Add access to real-time information to our AI agent. The agent will finally be able to answer questions like “What is the weather forecast?” by calling the tools and execute functions.
Learn More
Let’s continue building intelligent Java applications with Spring AI!




