
In Part 5 of this series, we added MCP to our AI agent, enabling dynamic tool integration without code changes. However, we discovered another limitation: when users wants to upload expense receipts, invoices, or travel documents, the agent can only process text—it cannot analyze images or extract information from visual documents.
Text-only AI agents miss critical information embedded in images, scanned documents, charts, and diagrams. In business scenarios like expense management, travel booking confirmations, or invoice processing, most information arrives as images or PDFs rather than structured text.
In this post, we’ll add multi-modal capabilities (vision and document analysis) and multi-model support to our AI agent, allowing it to analyze images, extract structured data from receipts, and use different AI models optimized for specific tasks.
Overview of the Solution
The Multi-Modal Challenge
Text-only AI agents cannot:
- Extract information from receipt images or scanned invoices
- Analyze charts, diagrams, or infographics
- Process travel booking confirmations (often PDFs with images)
- Understand visual context in documents
- Verify expense compliance from uploaded receipts
Users expect to upload a photo of their restaurant receipt and have the AI extract the amount, date, merchant, and check policy compliance automatically.
We’ll solve this with multi-modal AI and multi-model architecture:
- Add vision-capable models that can analyze images and documents
- Create specialized service for document analysis with expense extraction
- Configure different models for different tasks (chat vs. document analysis)
- Route requests based on content type (text vs. image/document)
What is Multi-Modal AI?
Multi-modal AI models can process and understand multiple types of input:
- Text: Natural language questions and responses
- Images: Photos, screenshots, diagrams
- Documents: PDFs, scanned receipts, invoices
- Combined: Text prompts with attached images
Vision-capable models like Claude Sonnet, Amazon Nova and some other models can “see” images and extract structured information, enabling use cases like:
- Expense receipt analysis and extraction
- Invoice processing and validation
- Travel document verification
- Chart and diagram interpretation
- Visual quality inspection
What is Multi-Model Architecture?
Different AI models excel at different tasks. A multi-model architecture uses:
- Chat Model: Optimized for conversational interactions, reasoning, and tool calling
- Document Model: Optimized for vision, document analysis, and structured data extraction
- Embedding Model: Optimized for semantic search and RAG (already using Titan Embeddings)
This allows you to choose the best model for each task while maintaining a unified user experience.
Architecture Overview
1 | User Request |
Key Spring AI Components
- ChatClient: Unified interface for all AI models
- Multi-Modal Support: Handle text, images, and documents in prompts
- Model Options: Configure different models per request
Prerequisites
Before you start, ensure you have:
- Completed Part 5 of this series with the working
ai-agentapplication - Java 21 JDK installed (Amazon Corretto 21)
- Maven 3.6+ installed
- Docker Desktop running (for Testcontainers with PostgreSQL/PGVector)
- AWS CLI configured with access to Amazon Bedrock
- Access to vision-capable models in Amazon Bedrock (Claude Sonnet, Amazon Nova)
Navigate to your project directory from Part 5:
1 | cd ai-agent |
Multi-Model Configuration
We’ll configure two models: one for chat interactions and one for document analysis.
Configure Models
Add model configuration to src/main/resources/application.properties:
1 | cat >> src/main/resources/application.properties << 'EOF' |
This configuration:
- Uses Claude Sonnet 4.5 for document analysis (vision-capable)
- Keeps the existing chat model configuration for conversations
- Allows independent model selection for different tasks
You can use different models for chat and documents. For example, use Nova Pro for chat (cost-effective) and Claude Sonnet for documents (superior vision capabilities).
Document Analysis Service
We’ll create a specialized service for analyzing images and documents with vision models.
Create DocumentChatService
Create the service that handles multi-modal document analysis:
1 | mkdir -p src/main/java/com/example/ai/agent/service |
Key features:
- Multi-modal prompts: Combines text and images in a single request
- Expense extraction: Structured prompt for extracting receipt information
- Policy compliance: Checks expenses against company policies (via RAG)
- Currency conversion: Uses tools to convert amounts to EUR
- Streaming response: Provides immediate feedback and streams results
Update ChatController
Update ChatController to route document requests:
src/main/java/com/example/ai/agent/controller/ChatController.java
1 | import com.example.ai.agent.service.DocumentChatService; |
The controller now:
- Accepts file uploads as base64-encoded strings
- Routes requests with files to DocumentChatService
- Routes text-only requests to ChatService
- Maintains the same streaming response interface
Update WebViewController
Enable multi-modal features in the UI:
src/main/java/com/example/ai/agent/controller/WebViewController.java
1 | ... |
This enables the file upload button in the web interface, allowing users to attach images and documents to their messages.
Testing Multi-Modal Capabilities
If you completed Part 5, you can either start the travel MCP server from Part 5, or comment out the MCP client configuration in
application.propertiesto test multi-modal features independently:
Let’s test document analysis with a tram ticket image:
1 | ./mvnw spring-boot:test-run |
Download the sample ticket image:
1 | # Download sample tram ticket |
Test in the UI at http://localhost:8080:
- Click the file upload button (📎)
- Select the
ticket-tram-cz.pngimage - Type “Analyze this expense receipt” in the message box
- Click Send
The AI will analyze the tram ticket image and extract:
1 | Analyzing document... |
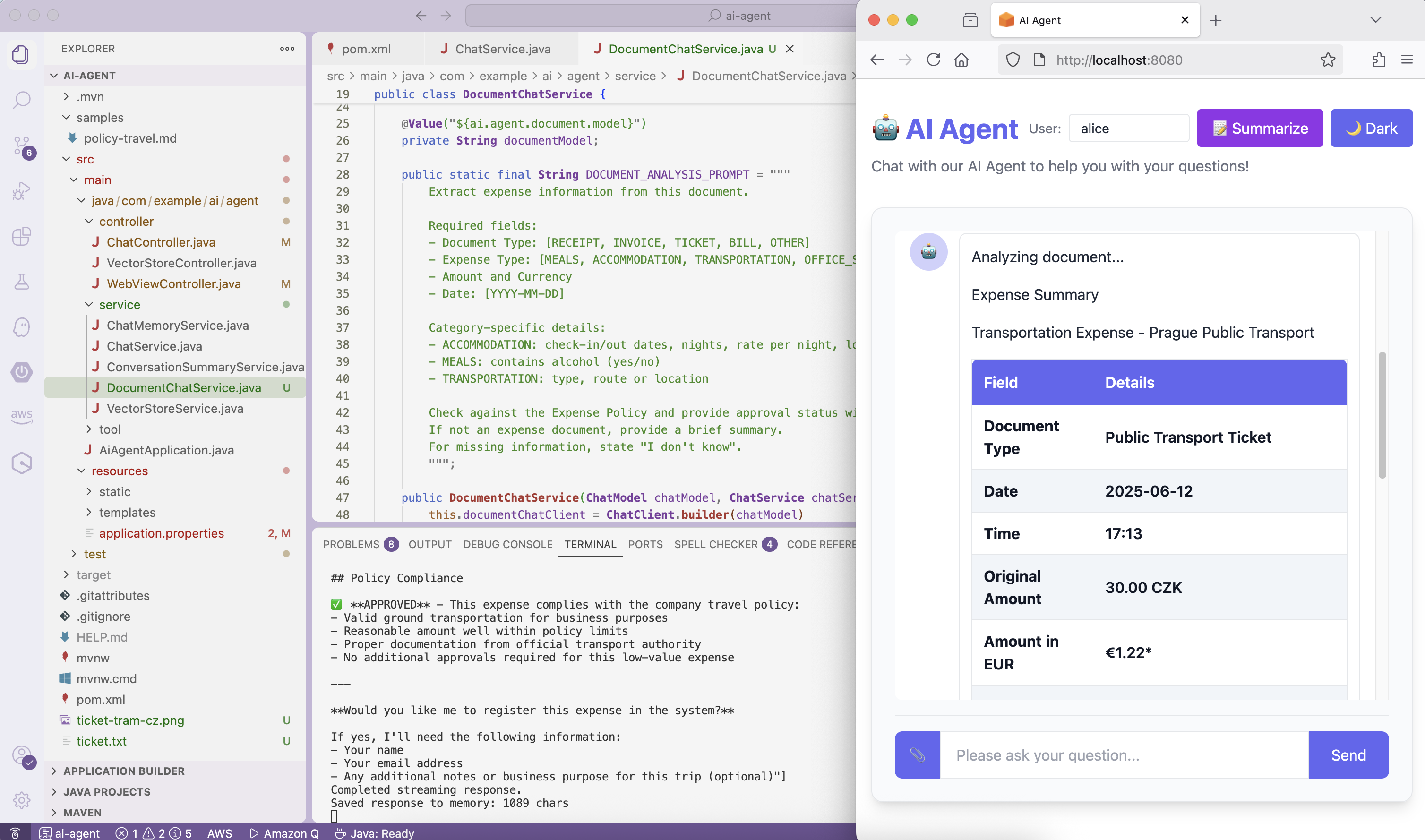
✅ Success! The AI agent can now analyze images and extract structured information.
You can also test in the UI at http://localhost:8080 - use the file upload feature to analyze receipts, invoices, or travel documents.
To test expense registration, you can download the
backendMCP server from the sample repository and connect your AI Agent to it using the techniques learned in Part 5. The backend server provides expense management tools that work seamlessly with document analysis.
How Multi-Modal Works
When you upload a receipt image, here’s what happens:
- Image upload: Browser converts image to base64 and sends to server
- Routing: ChatController detects file and routes to DocumentChatService
- Vision analysis: Claude Sonnet analyzes the image and extracts expense data
- Policy check: RAG retrieves relevant expense policies
- Currency conversion: Tools convert amounts to EUR if needed (if backend server is connected)
- Structured response: Formats results with approval status
The AI “sees” the receipt image and extracts text, amounts, dates, and merchant information automatically.
Multi-Model Benefits
Using different models for different tasks provides:
- Cost optimization: Use cheaper models for simple chat, expensive models for complex vision tasks
- Performance optimization: Vision models for documents, fast models for chat
- Capability matching: Use models with specific strengths (Claude for vision, Nova for speed)
- Flexibility: Switch models without changing application code
Cleanup
To stop the application, press Ctrl+C in the terminal where it’s running.
The PostgreSQL container will continue running (due to withReuse(true)). If necessary, stop and remove it:
1 | docker stop ai-agent-postgres |
(Optional) To remove all data and start fresh:
1 | docker volume prune |
Commit Changes
1 | git add . |
Conclusion
In this post, we’ve added multi-modal and multi-model capabilities to our AI agent:
- Multi-Modal Support: Analyze images, receipts, invoices, and documents
- Document Analysis Service: Specialized service for vision-based extraction
- Multi-Model Architecture: Different models for chat vs. document analysis
- Expense Extraction: Structured data extraction from receipt images
- Policy Compliance: Automatic checking against company policies
Our AI agent now has a complete, production-ready architecture: memory (Part 2), knowledge (Part 3), real-time information (Part 4), dynamic tool integration (Part 5), and multi-modal capabilities (Part 6). It can handle text conversations, analyze images, integrate with any service via MCP, and use the best AI model for each task—all essential capabilities for enterprise AI applications.
What’s Next
Explore production deployment patterns, monitoring and observability, security best practices, and scaling strategies for AI agents in enterprise environments.
Learn More
- Spring AI Multi-Modal Documentation
- Amazon Bedrock Converse API
- Claude Vision Capabilities
- Amazon Nova Models
- Part 1: Create an AI Agent
- Part 2: Add Memory
- Part 3: Add Knowledge
- Part 4: Add Tools
- Part 5: Add MCP
Let’s continue building intelligent Java applications with Spring AI!
Let’s continue this journey in 2026!




